
EVEN THE PEANUT LOOKS EXPENSIVE
- Feb 17
- 6 min read
Updated: Apr 5

The waves converged. What happened next?
A companion to Cheaper than a Peanut (December 2024)
In December 2024, Brightbeam published Cheaper than a Peanut, tracking the exponential decline in compute costs from (a theoretical) $20 trillion per GFLOP in 1945 to roughly a penny in 2023.
We mapped the history of computing as a series of waves - mainframes, personal computing, the internet, cloud, mobile - each crashing ashore faster than the last. We argued that a second meta wave, the AI era, had begun in 2012, and that its pace was qualitatively different from anything before it.
The thesis was straightforward: intelligence was becoming so cheap, evolving so fast, that organisations which failed to grasp the trajectory would be overtaken by those that did.
Fourteen months later, the waves metaphor needs revising. What we described were waves building on the horizon, each larger than the last but arriving at decreasing intervals. What has happened since is something else. The waves did not simply continue - they converged. Cost collapse, algorithmic breakthroughs, agent autonomy, coding automation - and an unprecedented flood of capital - all arrived in the same fourteen-month window. The individual waves are no longer distinguishable. They have merged into a single wall of water.
This companion piece traces what happened - with the specific numbers, the charts, and the implications. It is not a revision of the original paper. It is an update from a world that moved faster than anyone expected.
THE COST CURVE BENT EVEN FASTER
Andreessen Horowitz coined the term “LLMflation” in November 2024, documenting that the cost of equivalent LLM performance drops roughly 10× every year - far outpacing Moore’s Law at 2× every 18 months.
Stanford’s HAI AI Index 2025 confirmed the trend: the cost to match GPT-3.5’s performance fell 280-fold between November 2022 and October 2024, from $20 per million tokens to just $0.07. Epoch AI’s rigorous analysis across six benchmarks found declines between 9× and 900× per year, with a median of 50× per year.
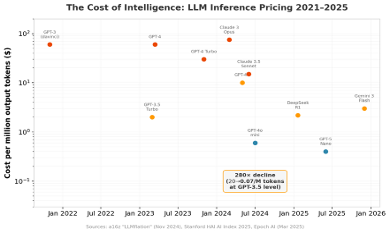
Figure 1: LLM inference pricing collapsed across every model tier, 2021–2025 (sources: a16z, Stanford HAI, Epoch AI)
At the model level, the trajectory is stark. GPT-4 launched in March 2023 at $60 per million output tokens. By July 2024, GPT-4o mini delivered comparable quality for $0.60 - a hundredfold drop in sixteen months. DeepSeek R1, released in January 2025 with full reasoning capabilities, priced its output at $2.19 per million tokens - 27× cheaper than OpenAI’s comparable o1.
Hardware followed. Cloud rental prices for NVIDIA H100 GPUs collapsed from a peak of $7–10 per GPU-hour in 2023 to as low as $1.49 on discount providers by late 2025 - a 64–75% decline. AWS cut H100 prices 44% in June 2025 alone.
Perhaps the most vivid illustration of the cost trajectory comes from Andrej Karpathy. In 2019, OpenAI trained GPT-2 on 32 TPU v3 chips for 168 hours at a cost of approximately $43,000. By July 2024, Karpathy reproduced the same model in 24 hours on a single 8×H100 node for $672. By early 2025, using his nanochat framework with improved algorithms and data quality, he matched GPT-2’s capability in 3 hours for $73. By February 2026, with FP8 training enabled, the time dropped to 2.91 hours and the cost to roughly $20 on spot instances - a 2,150× reduction in seven years. Karpathy has dubbed GPT-2 “the new MNIST”: a frontier model from 2019, now a trivial training exercise. What was once guarded as too dangerous to release in full is now a weekend project for a student with a credit card.
The critical paradox persists: the cost to reach yesterday’s frontier collapses exponentially, but the cost to push today’s frontier keeps rising. Stanford HAI found companies spent 28× more on average training their latest flagship. But this divergence is precisely what democratises AI - what cost $100 million to create in 2023 can be replicated for $5 million in 2025.
THE EFFICIENCY BREAKTHROUGH
Those who have witnessed a tsunami describe a strange phenomenon that precedes it: the water pulls back from the shore, exposing the seabed, before the wall arrives. In the AI world, DeepSeek was that moment - a sudden, disorienting retreat of assumptions about what scale and cost were required, immediately followed by a surge that reshaped the landscape.
On Christmas Day 2024, Chinese startup DeepSeek released V3, a 671-billion-parameter mixture-of-experts model trained on 2,048 H800 GPUs for a claimed $5.6 million - independently verified as plausible by Epoch AI. For context, Meta’s Llama 3.1 used 12× more GPU hours; GPT-4 reportedly cost over $100 million. Three weeks later came R1, an open-source reasoning model matching OpenAI’s o1 across maths, code, and reasoning benchmarks at 27× lower inference cost.
The market reaction on 27 January 2025 was immediate: NVIDIA lost approximately $593 billion in market capitalisation - the largest single-day loss for any company in stock market history. The Nasdaq fell 3.1%. Roughly $1 trillion evaporated from U.S. tech stocks as investors questioned whether the infrastructure buildout was overbuilt. Satya Nadella swiftly invoked Jevons Paradox - that efficiency gains expand total demand - and the recovery proved him right. Meta raised its 2025 AI spending guidance 50% just days later.
DeepSeek’s lasting impact was not the market drama but the paradigm shift. The industry moved decisively from pure scaling (“throw more data centres at it”) toward algorithmic efficiency: reinforcement learning, mixture-of-experts routing, test-time compute, and sparse attention. The open-source ecosystem it energised exploded - Hugging Face surpassed two million models by late 2025, with the second million arriving in just 335 days versus over a thousand for the first. The “post-scaling era” had begun.
MODELS GOT SMARTER FASTER THAN ANYONE PREDICTED
The fourteen months since December 2024 produced a benchmark annihilation unprecedented in AI history. Every major laboratory released multiple frontier models, and the pace of capability improvement visibly accelerated.

Figure 2: Benchmark scores, December 2024 state-of-the-art versus February 2026 (sources: OpenAI, Anthropic, Google DeepMind, Scale AI)
On GPQA Diamond - PhD-level science questions - GPT-5.2 now scores 92.4%, surpassing the human expert baseline of 89.8%. On AIME 2025, multiple models achieve a perfect 100%. FrontierMath, introduced with scores around 2%, has seen a 20× improvement to 40.3%. Humanity’s Last Exam, designed in January 2025 as a deliberately hard ceiling, rose from 8.8% to roughly 46% in under twelve months - a 5× improvement on questions curated to resist exactly this kind of progress.
In just 25 days between 17 November and 11 December 2025, four frontier models launched - Grok 4.1, Gemini 3 Pro, Claude Opus 4.5, and GPT-5.2 - representing more capability advancement in under a month than most prior years achieved in total. Context windows expanded from 128–200K tokens to 10 million (Llama 4 Scout), a 50–78× increase. The reasoning model revolution, sparked by o1 and turbocharged by DeepSeek R1’s demonstration that reasoning could be cheaply replicated, defined 2025’s progress.

Figure 3: SWE-bench Verified progression - AI software engineering capability climbed from ~16% to 82% in 16 months (sources: SWE-bench leaderboard, Epoch AI)
AI CODING AGENTS REDEFINED SOFTWARE DEVELOPMENT
When Cheaper than a Peanut was published, Claude Code did not exist. By November 2025 it had crossed $1 billion in annualised revenue - just six months after its general availability launch. By January 2026, Anthropic released Claude Cowork, a GUI coding tool that was itself almost entirely written by Claude Code. The tool writing the tools: a recursive loop that captures the era perfectly.
Cursor, from startup Anysphere, became the fastest-growing SaaS company in history - scaling from $100 million revenue in 2024 to $1 billion annualised by November 2025, with its valuation rocketing from $2.5 billion to $29.3 billion in under a year. GitHub Copilot reached 20 million users by July 2025, contributing 46% of all code written by active users (up from 27% at its 2022 launch). According to a SemiAnalysis report in February 2026, Claude Code alone now accounts for 4% of all public GitHub commits - over 135,000 per day - with a 42,896× growth in thirteen months. SemiAnalysis projects this will reach 20% of all daily commits by the end of 2026.

Figure 4: Claude Code’s exponential growth on GitHub - from near-zero to 135,000 daily commits in 13 months (source: adapted from SemiAnalysis, February 2026)
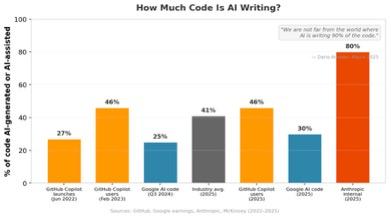
Figure 5: Percentage of code that is AI-generated or AI-assisted, by source (sources: GitHub, Google, Anthropic, McKinsey)
“We are not far from the world - I think we’ll be there in three to six months - where AI is writing 90 percent of the code.”
- Dario Amodei, Council on Foreign Relations, 10 March 2025
By September 2025 at Dreamforce, Amodei confirmed: “Within Anthropic and within a number of companies that we work with, that is absolutely true now.” Microsoft CTO Kevin Scott predicted AI will write 95% of code within five years. At Google, over 30% of new code is now AI-generated. The industry average sits at roughly 41%, with 82% of developers using AI coding tools daily or weekly.
Productivity data from controlled studies shows 55% faster task completion (GitHub/Accenture, 4,800 developers) and 75% reduction in pull request times. A striking contrarian finding from METR’s July 2025 trial found experienced open-source developers actually 19% slower with AI tools - despite believing they were 20% faster. This suggests the J-curve of adoption applies to individuals as well as organisations: the dip before the surge.
Want to know how it ends? Part 2 continues with the rise of autonomous agents, the disruption of knowledge work, the extraordinary convergence in leadership timelines - and the question of whether the world is ready.






