
GROUND TRUTH BY EXAMPLE
- Dec 17, 2025
- 19 min read

An Essential Pattern for Intelligence in Enterprise Systems
Executive Summary
Every successful system - whether powered by human intelligence, traditional code, machine learning, or generative AI - requires a clear specification of what 'correct' looks like. This fundamental truth of systems design has become more critical than ever as organisations deploy increasingly sophisticated forms of intelligence.
This whitepaper introduces a practical methodology that transforms abstract requirements into concrete specifications through real-world examples. We call it: 'Ground Truth by Example'. When organisational consensus is created through example-driven development, rapid deployment of intelligent systems follows. And continuous improvement mechanisms are established.
Drawing from implementations across healthcare, insurance, biopharmaceutical manufacturing, and complex regulated industries, we demonstrate how this pattern makes the historically intractable problem of validation both manageable and iterative.
The pattern's power lies not in technical sophistication, but in recognising a universal truth: all systems - and all intelligence - require clear examples of success, mechanisms for correction, and metrics for performance. By making evaluation datasets the foundation of the entire development lifecycle (Discovery, Alpha, Beta, Live), organisations can finally move from endless pilots to production deployments that deliver measurable value.
We want to make digital intelligence second nature. And that means we need to make it understandable and reliable.
1. Ground Truth: The Foundation of All Knowledge
1.1 From Scientific Method to Digital Intelligence
Every advance in human knowledge has followed the same pattern: hypothesis, test against reality, refine. The scientific method itself is fundamentally about ground truth - we propose how the world works, then test our hypothesis against observable examples. We cannot build knowledge without concrete examples that prove or disprove our understanding.
This principle extends far beyond laboratories:
Science: Every hypothesis is tested against experimental data
Medicine: Every treatment validated through clinical trials
Engineering: Every design is proven through prototypes
AI Research: Every model trained on labelled examples
Every discipline uses some form of evaluation to help refine ideas.
At Brightbeam, we believe digital intelligence should be as natural as human intelligence - 'second nature' to organisations. Achieving this requires making success obvious through examples, not ambiguous through abstraction. Being able to describe what good looks like using the same principles for other foundational knowledge is an essential starting point.
1.3 The Universal Challenge
Every organisation faces the same paradox when deploying intelligence:
Training new employees: How do we convey what a 'good' customer service call summary looks like?
Building ML models: What features define a valid insurance claim?
Deploying Gen AI: Which information must appear in a regulatory filing?
As one senior engineer observed: 'Getting the system to output the 'right thing' depends on who you ask at the customer.' This isn't a technology problem - it's a specification problem that exists regardless of the intelligence type.
Enterprise environments often exhibit what we call 'decision paralysis syndrome':
Leadership punishes wrong decisions but ignores non-decisions
Nobody wants to approve production deployment
Teams iterate endlessly on 'good enough' without clear success criteria
Different stakeholders have conflicting definitions of 'correct'
This paralysis costs organisations millions in delayed deployments and missed opportunities.
2. Ground Truth by Example: Making Intelligence Second Nature
2.1 The Brightbeam Philosophy
True helpfulness means making the complex simple, the ambiguous clear, and the theoretical practical. Ground Truth by Example embodies this philosophy by transforming abstract requirements into concrete understanding that becomes second nature to organisations.
The pattern rests on three fundamental principles:
1. No Blank Page - Be Genuinely Helpful
Never force stakeholders to define correctness from scratch, but equally don't overwhelm them with thousands of examples to validate. As one practitioner explained the dual challenge: 'The worst thing to do would be to ask them to give me a spreadsheet with all the answers from scratch - that's the blank page problem. But equally bad is dumping a thousand rows and asking them to mark each one right or wrong - that's an overwhelming volume problem.'
The solution: Generate manageable batches of examples they can react to and refine. Start with 20-50 examples, not 2000. This helpfulness transforms an impossible task into a manageable conversation. Each batch can help refine the scope and manage more edge cases and nuances.
2. Specification by Example - Make Success Obvious
Define success through concrete examples, not abstract rules. Like the scientific method, we form hypotheses then test them against reality. 'This call was about checking validity of a no claims bonus - the letters 'NCB' must appear in the summary.' Obvious, testable, measurable.
3. Iterative Refinement Through DABL - Build Knowledge Systematically
Evaluation evolves naturally through each phase:
Discovery: Form hypotheses about what success looks like
Alpha: Test hypotheses with initial examples (real or synthesised)
Beta: Validate with comprehensive datasets, achieve consensus
Live: Continuously disprove and improve our understanding
This mirrors how all knowledge advances - through systematic testing against ground truth.
2.2 The DABL Implementation Framework
Ground Truth by Example integrates seamlessly with DABL, with evaluation datasets evolving naturally through each phase:
DISCOVERY PHASE
Form hypotheses about what 'good' looks like
Identify existing examples from production systems
Interview stakeholders about success criteria
Document assumptions to test
Deliverable: Evaluation strategy with initial hypotheses
ALPHA PHASE
Generate examples from two sources:
Real data: Historical outputs, production samples
Synthetic: AI-generated examples based on understanding
Create initial evaluation dataset
Test hypotheses through stakeholder review
Identify critical must-have/must-not-have elements
Deliverable: Alpha evaluation dataset with emerging consensus
BETA PHASE
Expand to comprehensive train/test/validate splits
Include edge cases discovered through testing
Achieve stakeholder sign-off on success criteria
Run parallel testing with current approaches
Deliverable: Production-ready evaluation framework
LIVE PHASE
Monitor production corrections as new ground truth
Track performance against evaluation metrics
Regular evaluation dataset updates
Continuous model/prompt refinement
Deliverable: Living evaluation system that improves over time
By Beta phase, teams should have robust datasets that make 'great' second nature to everyone - from engineers to executives. The beauty is that examples can come from anywhere: existing systems provide real ground truth, while AI can synthesise examples to test edge cases and explore possibilities.
3. Why Ground Truth Drives Intelligence Breakthroughs
3.1 The DeepMind Lesson
One of Google DeepMind's significant insights wasn't about neural networks or computing power - it was about choosing problems with ground truth that scale massively. Here are some of their examples where success and failure are unambiguous:
Chess: Every move either improves or worsens your position
Go: 30 million historical games showing winning patterns
StarCraft: Thousands of replays demonstrating successful strategies
Protein Folding: Known structures providing validation targets
Mathematical Proofs: Provable mathematics that are rooted in hundreds and thousands of years of work
Code: Billions of lines of code that either pass or fail tests
This abundance of ground truth enabled rapid iteration and clear progress measurement. Without it, even the most sophisticated algorithms aimlessly wander.
3.2 The Enterprise Challenge: Synthesis and Reality
Enterprises lack the luxury of millions of chess games or the entire internet as training data. But they don't need it. They need a smart mix of real and synthetic examples that cover both common cases and critical edge cases.
The Synthesis Strategy:
Start with Reality: Gather 20-100 real examples from production or historical data
Synthesise for Coverage: Use AI to generate examples that test hypotheses and fill gaps
Mix Thoughtfully: Combine real and synthetic in ratios that match your confidence (70% real when uncertain, 30% real when domain is well-understood)
Hunt for Outliers: Deliberately generate edge cases, failure modes, and 'what if' scenarios
Handling Distribution Challenges:
Every system will encounter out-of-distribution inputs - the customer who speaks in dialect, the form filled out creatively, the edge case nobody imagined. Ground Truth by Example handles this through:
Outlier Collection: Flag and collect unexpected inputs from production
Quarterly Reviews: Regular evaluation dataset updates to incorporate new patterns
Graceful Degradation: Define how systems should behave when uncertain
Human-in-the-Loop: Clear escalation paths for low-confidence outputs
AI as Evaluation Assistant:
Modern AI isn't just what we're evaluating - it's a powerful tool for evaluation itself:
Gap Analysis: 'Here are 100 examples. What patterns are missing?'
Consistency Checking: 'Do these success criteria contradict each other?'
Edge Case Generation: 'What unusual inputs might break this?'
Coverage Assessment: 'What percentage of real-world cases do these examples cover?'
Quality Validation: 'Are these examples clear and unambiguous?'
This creates a virtuous cycle: AI helps build better evaluation datasets, which create better AI systems, which help build even better evaluations.
4. Case Studies Across Industries
4.1 Insurance: Call Summarisation
Challenge: Validate call summaries without clear success criteria across departments
Implementation:
Discovery: Found agents manually writing summaries with no consistency
Alpha: Generated 200 redacted call summaries using GPT-4
Beta: Defined must-have abbreviations (NCB, MOT, etc.), tracked agent edits using Levenshtein distance
Live: Achieved 85% acceptance rate within 3 months
Key Insight: 'Even using evaluation as a forcing function to get a room full of people on the customer side to agree what the right answer is.'
4.2 Health Insurance: Document Extraction
Challenge: Extract 20-30 fields from insurance claim forms with varying formats
Implementation:
Discovery: Identified 1000 historical forms with manual processing notes
Alpha: LLM generated initial extractions, split into 10 spreadsheets for parallel review
Beta: Domain experts corrected outputs, built consensus on ambiguous fields
Live: Achieved 95% accuracy after three iteration cycles
Key Insight: Making correction easy trumps asking for perfect specification upfront.
4.3 BioPharma: Clinical Protocol Deviation Detection
Challenge: Identify protocol deviations in clinical trial documentation
Implementation:
Discovery: Collected 500 historical deviation reports across 3 trial types
Alpha: AI flagged potential deviations, clinical team reviewed for false positives/negatives
Beta: Built evaluation set covering 15 deviation categories with severity ratings
Live: Reduced deviation detection time from 3 days to 30 minutes with 92% accuracy
Key Examples:
Must detect: 'Participant took 100mg instead of prescribed 50mg'
Must ignore: 'Participant arrived 5 minutes late' (within acceptable window)
Context-dependent: 'Missed dose' (critical for oncology, minor for supplements)
4.4 Manufacturing: Quality Control Report Generation
Challenge: Generate quality control reports for automotive parts manufacturer
Implementation:
Discovery: Analysed 2 years of QC reports across 5 production lines
Alpha: Generated draft reports, identified critical measurements that must always appear
Beta: Built evaluation dataset with tolerance specifications, failure mode descriptions
Live: 100% capture of critical defects, 60% reduction in report generation time
Key Examples:
Must include: Exact tolerance measurements ('Diameter: 25.4mm ±0.1mm')
Must flag: Out-of-spec conditions ('FAILED: 25.7mm exceeds tolerance')
Must reference: ISO standards and batch numbers for traceability
4.5 Financial Services: Regulatory Filing Validation
Challenge: Ensure regulatory filings contain all required disclosures
Implementation:
Discovery: Mapped regulatory requirements to historical filing sections
Alpha: Generated example filings, legal team marked missing/incorrect sections
Beta: Created evaluation set with 200 must-have phrases across 10 filing types
Live: Zero regulatory penalties in first year, 70% reduction in legal review time
Key Examples:
Must contain: 'Risk Factors,' 'Forward-Looking Statements,' specific legal language
Must match: Numerical consistency across sections (revenue figures, dates)
Must avoid: Outdated regulatory references or non-compliant terminology
5. The Economics of Good Enough: Why Business Metrics Trump Perfection
5.1 Finding Your North Star Business Metric
The gold standard for any Ground Truth evaluation isn't technical accuracy - it's a clear business metric that quantifies the cost of both 'go' and 'no go' decisions. Without this, teams waste weeks pursuing meaningless improvements while value sits on the table.
The North Star Formula:
Value of Going Live Now = (Improvement × Scale × Time) - (Error Cost × Error Rate)
Cost of Waiting = (Potential Value × Delay) + (Additional Development Cost)
When Value of Going Live > Cost of Waiting, deploy immediately.
5.2 A real example: The 72% Solution
Consider a real call summarisation project:
Business Goal: Increase call handling capacity without hiring staff Functional Metric: Reduce call handling time per agent Current Performance: 72% accuracy (28% require human edits)
The perfectionist view: 'We need 95% accuracy before deployment.'
The business view:
72% accuracy still saves 30 seconds per call
50 agents × 100 calls/day × 30 seconds = 41.6 hours daily capacity
At £25/hour, that's £1,040 value per day
Two-week delay costs £14,560 in lost productivity
Plus: We're not collecting production data to improve
The Decision: Deploy at 72%, improve in production.
5.3 The Hidden Cost of Perfection
Teams often don't calculate the true cost of delay:
Visible Costs:
Additional development time
Extended testing cycles
Stakeholder review sessions
Hidden Costs:
Opportunity cost of delayed value
Competitor advantage while you perfect
Team morale from endless iteration
Lost production training data
Stakeholder fatigue and disengagement
The Reality Check: A system that's 70% accurate and deployed beats a 95% accurate system still in development. Every day of delay is a day of lost value and lost learning.
5.4 Reframing the Accuracy Conversation
Instead of asking 'Is it accurate enough?' ask 'What's the business impact at this accuracy level?'
Traditional Framing:
'The model is only 75% accurate'
'25% of outputs need correction'
'We're not meeting the threshold'
Business Framing:
'We save 3 minutes per transaction even with corrections'
'That's £50,000 monthly value at current accuracy'
'Each 5% accuracy improvement adds £8,000 monthly value'
'We can deploy now and improve while earning'
5.5 The Production Data Advantage
Delaying deployment for marginal improvements ignores a crucial fact: production data is golden for improvement.
Pre-Production Reality:
Limited test data
Synthetic examples
Stakeholder guesses about edge cases
Production Goldmine:
Real user inputs with full variety
Actual edge cases you never imagined
True distribution of problems
Continuous correction data for retraining
Every day you delay deployment is a day you're not collecting the data that would actually improve your system.
5.6 Setting Deployment Thresholds
Don't set arbitrary accuracy thresholds. Set business value thresholds:
Bad Threshold Setting: 'We need 95% accuracy' (Why? Says who? Based on what?)
Good Threshold Setting: 'We need to save at least 2 minutes per transaction to justify the change management cost'
Threshold Calculation Framework:
Calculate current process cost
Determine minimum valuable improvement
Find accuracy level that delivers that improvement
Add safety margin for critical failures
Deploy when threshold is met
5.7 The Go/No-Go Decision Matrix
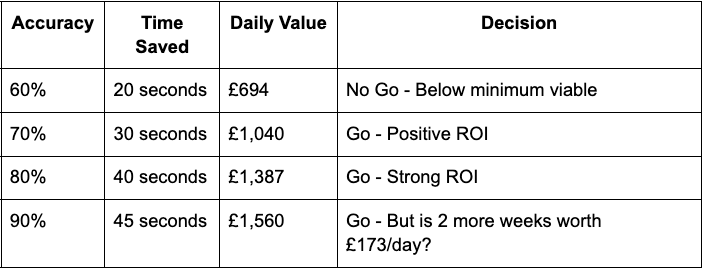
5.8 Managing Stakeholder Expectations
The key to overcoming resistance isn't achieving perfection - it's setting proper expectations:
Week 1 Conversation: 'Our north star is 30-second time savings. Based on initial tests, we can achieve this at 70% accuracy. Should we deploy at 70% or spend two more weeks reaching 85%?'
The Business Answer: 'Deploy at 70%. Two weeks of productivity gains pays for a lot of error correction.'
The Framework:
Always lead with business impact, not accuracy percentages
Show the cost of delay in monetary terms
Emphasise continuous improvement post-deployment
Highlight production data advantage
Set review cycles for improvement targets
5.9 The Compound Effect of 'Good Enough'
Organisations that deploy at 'good enough' create compound advantages:
Month 1: 70% accurate, saving 30 seconds/call Month 2: 75% accurate (production data training), saving 35 seconds/call Month 3: 80% accurate, saving 40 seconds/call Month 6: 85% accurate, saving 45 seconds/call
Meanwhile, the perfectionist organisation: Month 1-2: Still developing trying to get to 90% and only achieving 70%-75% Month 3: Still developing trying to get to 90% and only achieving 75%-78% Month 6: Still < 80% because they have limited production data and the fuel to drive improvements
The Six-Month Score:
'Good Enough' Team: 6 months of value, better final system
'Perfectionist' Team: 3 months of value, static system
5.10 The Executive Conversation
Stop having technical conversations with executives. Have business conversations:
❌ Wrong: 'We've achieved 78.3% F1 score on our validation set'
✅ Right: 'We're ready to save £50,000 monthly at current performance, with clear path to £70,000 monthly within 90 days of deployment'
❌ Wrong: 'We need two more sprints to improve accuracy'
✅ Right: 'We can deploy now and earn £25,000 while improving, or wait two weeks for an extra £3,000 monthly value'
The Ground Truth by Example pattern isn't about achieving perfect accuracy - it's about reaching good enough accuracy to deliver business value, then improving continuously with production data. The organisations that understand this economics of 'good enough' will capture value while their competitors are still perfecting their pilots.
6. Implementation Guide: Making Ground Truth Second Nature
6.1 Discovery Phase
Objectives: Understand the problem space and form testable hypotheses
Being Helpful Means:
Not asking for blank requirements documents
Bringing examples from similar problems
Facilitating hypothesis formation, not demanding answers
Activities:
Audit existing systems for real examples
Interview stakeholders about their definition of success
Collect production data where available
Synthesise initial examples to test understanding
Document hypotheses to validate
Deliverables:
Evaluation strategy with clear hypotheses
Initial example collection (real or synthetic)
Stakeholder map with decision rights
Success criteria assumptions to test
Red Flags:
No consensus even on basic success criteria
Outputs not connected to any business case
Complete absence of any examples
Conflicting interpretations of requirements
6.2 Alpha Phase
Objectives: Test hypotheses through concrete examples
Being Helpful Means:
Generating examples for stakeholders to react to
Making review process as easy as possible
Facilitating consensus, not forcing it
Activities:
Generate examples from two sources:
Structure for efficient review (chunking strategy)
Run facilitated review sessions
Document all corrections and reasoning
Build consensus on controversial examples
Deliverables:
Alpha evaluation dataset
Must-have/must-not-have element registry
Validated (or disproven) hypotheses
Performance baseline metrics
Success Criteria:
Stakeholder consensus on most examples
Clear documentation of edge cases
Efficient review process established
6.3 Beta Phase
Objectives: Build production-ready evaluation framework
Being Helpful Means:
Making success criteria obvious to everyone
Providing confidence through comprehensive testing
Enabling go/no-go decisions with clear data
Activities:
Expand evaluation dataset for comprehensive coverage
Create train/test/validate splits
Include failure modes and edge cases discovered
Run parallel testing with current approaches
Conduct performance characteristic analysis
Deliverables:
Comprehensive evaluation dataset
Performance comparison matrix
Clear go/no-go decision criteria
Beta test results report
Making Great 'Second Nature': By Beta completion, everyone - from engineers to executives - should instinctively know what great looks like. The evaluation dataset becomes organisational memory, encoding collective understanding of success.
6.4 Live Phase
Objectives: Continuous improvement through production ground truth
Being Helpful Means:
Making performance transparent
Enabling continuous improvement
Celebrating progress, not demanding perfection
Activities:
Monitor all production corrections as new ground truth
Regular evaluation dataset updates
Performance trending analysis
Model/prompt refinement cycles
Stakeholder satisfaction tracking
Deliverables:
Living evaluation system
Performance dashboards
Improvement reports
ROI documentation
The Second Nature Test: When new team members can understand what 'good' looks like by reviewing your evaluation datasets, you've succeeded. When stakeholders stop debating quality because examples make it obvious, you've made intelligence second nature.
6.5 Success Metrics Across Phases
Consensus Speed: Time to agreement on 90% of examples
Correction Rate: Percentage of outputs requiring modification
Edit Distance: Average changes needed per output
Deployment Velocity: Time from pattern implementation to production
Business Impact: Measurable improvement in target metrics
7. Tools and Getting Started
7.1 Tools for Ground Truth Evaluation
The Tool Spectrum
While Ground Truth by Example can work with simple spreadsheets, the right tools accelerate progress:
Basic Tools (Week 1 Start):
Spreadsheets: Google Sheets or Excel with columns for input, expected output, actual output, corrections
Version Control: Git for tracking changes to evaluation datasets
Diff Tools: Simple text comparison to track changes between versions
Evaluation Platforms:
LangSmith: Comprehensive LLM evaluation and monitoring
Weights & Biases: ML experiment tracking with dataset versioning
Evidently AI: Model monitoring and evaluation frameworks
Phoenix by Arize: Observability for evaluation and drift detection
Enterprise Solutions:
Scale AI: Human-in-the-loop evaluation at scale
Labelbox: Data labelling and quality management
Dataiku: End-to-end MLOps including evaluation
Custom Platforms: Built on your existing data infrastructure
The Minimum Viable Evaluation Stack
For teams starting today:
Google Sheets Template with:
Simple Python Script for running evaluations and calculating metrics
Basic Dashboard showing accuracy trends and failure patterns
AI-Powered Evaluation Tools
Use AI to accelerate evaluation dataset creation:
Generate edge cases from normal examples
Check for contradictions in success criteria
Identify gaps in coverage
Suggest missing test cases
7.2 Getting Started: A Practical Guide for Engagement Leads
Week 1: Discovery and Hypothesis Formation
Monday-Tuesday: Gather What Exists
Request existing documentation, test cases, or quality checks
Ask for 5-10 examples of 'good' outputs if available
Document what decisions the system needs to make
Wednesday-Thursday: Form Initial Hypotheses
Write down what you think success looks like
Create 10-20 synthetic examples using AI
Identify the most critical decisions/outputs
Friday: Initial Stakeholder Review
Show synthetic examples in a workshop
Ask: 'What's wrong with these?'
Document all corrections and reasoning
Key Questions for Stakeholders:
'Can you show me one example of this done well?'
'What would definitely be wrong in an output?'
'What's the most important thing to get right?'
'What variations do you see in practice?'
'When would you escalate to a human?'
Week 2: Building Your Alpha Dataset
Synthesis + Reality Mix:
Take 20 real examples from production (if available)
Generate 30 synthetic examples covering main use cases
Add 10 edge cases that might break things
Mix them together randomly
The Chunking Strategy:
Never present more than 50 examples at once
Break into themed batches
Assign different batches to different reviewers
Allow 1 hour per 25 examples for review
Running Efficient Review Sessions:
Pre-work: Send examples 24 hours ahead
Focus Time: 90-minute maximum sessions
Structure: Goals → Examples → Patterns
Output: Clear must-have/must-not-have list
7.3 Common Pitfalls and Solutions
'We need more examples' → Start with 50, not 500. Quality over quantity.
'Different stakeholders disagree' → Document disagreement, escalate for decision, use example to force clarity.
'The examples don't cover everything' → Cover 80% well, add edge cases in Beta, improve continuously in Live.
'It takes too long to review' → Use AI to pre-filter obvious cases, only review borderline examples.
'We don't have any real examples' → Generate synthetic examples from requirements, use them to elicit reactions.
8. Choosing Your Evaluation Approach
8.1 The Evaluation Method Spectrum
Not all evaluations are created equal. Choose your approach based on task complexity, stakes, and resources:
Simple Binary Checks (Fastest, Cheapest)
Exact match validation
Regex pattern matching
Schema compliance
Use when: Clear right/wrong answers exist
LLM as Judge (Fast, Scalable)
Single model evaluates outputs
Consistent rubric application
Good for subjective quality assessment
Use when: Need to evaluate thousands of examples quickly
LLM Jury System (Balanced, Robust)
Multiple models vote on quality
Reduces single-model bias
Weighted consensus mechanisms
Use when: High-stakes decisions need validation
Human Expert Review (Slow, Authoritative)
Domain experts apply rubrics
Captures nuanced judgment
Builds organisational consensus
Use when: Regulatory compliance or safety critical
Composite Pipeline (Comprehensive, Expensive)
Automated first pass
LLM review for borderline cases
Human review for failures
Production monitoring
Use when: Mission-critical systems
8.2 Matching Method to Context

8.3 The Evolution Path
Most organisations evolve through these stages:
Stage 1: 'Just Make It Work'
Basic exact match testing
Manual spot checks
Spreadsheet tracking
Stage 2: 'Scale the Validation'
LLM as Judge for bulk evaluation
Systematic rubrics
Automated metrics
Stage 3: 'Production Grade'
Multi-method validation
Continuous monitoring
Feedback loops
Stage 4: 'Self-Improving System'
Automatic evaluation updates
Drift detection
Adaptive thresholds
8.4 Red Flags in Evaluation Design
Watch for these common mistakes:
❌ Over-engineering Early: Using a jury system for a proof of concept ❌ Under-engineering Late: Using only exact match for production ❌ Single Point of Failure: Only one evaluation method ❌ No Human in the Loop: Fully automated for subjective tasks ❌ Perfect as Enemy of Good: 100% human review when 10% sampling would suffice
✅ Start Simple: Basic evaluation that actually runs ✅ Add Sophistication Gradually: Layer methods as you learn ✅ Multiple Perspectives: Combine automated and human review ✅ Focus on Decisions: Evaluate what matters for go/no-go ✅ Continuous Improvement: Every production output teaches
The key insight: Your evaluation method should match your confidence level. Low confidence requires more human review. High confidence allows more automation. Ground Truth by Example helps you systematically build that confidence.
9. The Future of Intelligence Validation
9.1 Evolution Through DABL
The pattern naturally evolves as organisations mature:
Discovery Maturity: From 'we don't know what good looks like' to 'we have hypotheses about success'
Alpha Maturity: From 'let's try something' to 'here are 100 examples to review'
Beta Maturity: From 'it seems to work' to 'we have comprehensive train/test/validate datasets proving it works'
Live Maturity: From 'it's in production' to 'we're continuously improving based on systematic feedback'
9.2 Organisational Maturity Model
Level 1: Ad Hoc
No systematic validation
Intelligence deployment fails or stalls
No consistent DABL process
Level 2: Example-Driven
Evaluation datasets for major deployments
DABL process followed but not optimised
Faster deployment, clearer success criteria
Level 3: Continuous
Evaluation embedded throughout DABL
Ongoing refinement from production
Rapid iteration and improvement
Level 4: Adaptive
Automatic intelligence selection based on task characteristics
Seamless human-AI collaboration
Ground truth drives all system decisions
9.3 The Convergence of Intelligence Types
As evaluation methods mature, we're seeing convergence:
Human training increasingly uses AI-generated examples
ML models learn from human corrections
Gen AI systems combine rule-based validation with neural approaches
Hybrid systems automatically select the best intelligence for each task
The future isn't human vs. AI - it's human and AI, with Ground Truth by Example as the common language between them.
10. Conclusion: Ground Truth as the Path to Second Nature Intelligence
The Universal Pattern of Knowledge
From Galileo dropping spheres from the Tower of Pisa to DeepMind conquering Go, the pattern remains constant: knowledge advances through testing hypotheses against ground truth. The scientific method isn't just for laboratories - it's how all understanding develops, whether human or digital.
What makes our current moment unique isn't the principle but the pace. When a modern AI system can generate thousands of outputs per hour, when clinical trials produce millions of data points, when manufacturing systems make split-second decisions - the cost of ambiguous success criteria becomes catastrophic. Yet the solution remains elegantly simple: concrete examples that make success obvious.
Making Digital Intelligence Second Nature
At Brightbeam, we believe organisations shouldn't have to think about whether their intelligence systems - human or digital - are working correctly. It should be as natural as knowing whether a conversation is going well, as obvious as recognising a familiar face.
Ground Truth by Example makes this possible by:
In Discovery: Forming hypotheses like scientists, not guessing like gamblers In Alpha: Testing understanding through examples, both real and synthesised In Beta: Building consensus through concrete specification, not abstract debate In Live: Learning continuously, with every interaction becoming ground truth
The Competitive Advantage of Helpfulness
Being genuinely helpful means acknowledging a simple truth: nobody wants to write requirements documents, but everyone can recognise good work when they see it. By generating examples for stakeholders to react to, we transform an impossible task (defining perfection in abstract) into a manageable conversation (improving concrete examples).
This helpfulness isn't just nice - it's strategically essential. Organisations that can rapidly achieve consensus, deploy with confidence, and improve continuously will outcompete those stuck in endless pilots and paralysing debates about requirements.
The Path Forward
Google DeepMind chose games because they provide perfect ground truth. Large Language Models train on the internet because every sentence teaches what comes next. Enterprises must create their own ground truth through examples.
The organisations that master Ground Truth by Example will achieve what others only promise:
Intelligence systems that actually work in production
Stakeholder consensus through concrete examples
Continuous improvement through systematic feedback
Digital intelligence that feels like second nature
As one engineering leader observed: 'We know these things to be true.' The difference between knowing and doing, between pilot and production, between promise and performance, lies in making ground truth obvious through examples.
In an era where 'AI transformation' has become a boardroom imperative, Ground Truth by Example offers something more valuable than technology - it offers a methodology rooted in the fundamental way all knowledge advances. It makes intelligence not just deployable, but natural, helpful, and continuously improving.
The elegance is in its universality. Whether training a new employee, building a machine learning model, or deploying the latest large language model, the requirement never changes: define success through examples, validate through comparison, improve through iteration. Make digital intelligence second nature by making success obvious.
Appendix A: Evaluation Dataset Structures and Methods
A.1 Core Evaluation Structures by Task Type
Classification Tasks
classification_evaluation:
task_type: 'multi_class_classification'
examples:
- input: 'Customer email about delayed shipment'
expected_label: 'complaint'
expected_confidence: 0.95
secondary_labels: ['shipping_issue', 'requires_response']
edge_case: false
metrics:
- precision_per_class
- recall_per_class
- f1_score
- confusion_matrix
Extraction Tasks
extraction_evaluation:
task_type: 'structured_data_extraction'
examples:
- input: 'Invoice #12345 dated 15/03/2024 for £2,500 + VAT'
expected_output:
invoice_number: '12345'
date: '2024-03-15'
amount: 2500
currency: 'GBP'
vat_included: false
must_extract: ['invoice_number', 'amount']
optional_extract: ['vat_included']
Generation Tasks
generation_evaluation:
task_type: 'summary_generation'
examples:
- input: 'Full customer call transcript...'
expected_elements:
must_include: ['policy_number', 'complaint_nature', 'resolution']
must_not_include: ['personal_medical_details', 'credit_card_full']
tone: 'professional'
max_length: 200
A.2 Advanced Evaluation Methods
LLM as Judge
llm_judge_config = {
'judge_model': 'gpt-4',
'evaluation_prompt': '''
Evaluate this AI response on:
1. Factual accuracy (0-10)
2. Completeness (0-10)
3. Tone appropriateness (0-10)
4. Compliance with guidelines (0-10)
''',
'threshold': 7.5
}
LLM Jury System
jury_evaluation = {
'jury_members': [
{'model': 'gpt-4', 'weight': 0.4},
{'model': 'claude-3', 'weight': 0.4},
{'model': 'gemini-pro', 'weight': 0.2}
],
'voting_method': 'weighted_average',
'consensus_threshold': 0.7
}
A.3 Domain-Specific Templates
Medical/Clinical
Safety-critical evaluation requirements
Medical expert review mandatory
Zero tolerance for hallucination
Must cite sources and express uncertainty
Financial Services
Regulatory compliance checking
Numerical accuracy to 6 decimal places
Complete audit trails
Mandatory disclaimers
Legal Documents
Exact citation accuracy
Legal terminology precision
Confidentiality checks
Privilege protection
Appendix B: Common Patterns and Anti-Patterns
Patterns That Work
Start with intelligence-generated examples
Chunk work for parallel processing
Track every edit for learning
Define success gradually through examples
Celebrate 'good enough' victories
Anti-Patterns to Avoid
Asking for blank specifications
Pursuing perfection before deployment
Ignoring domain expert corrections
Over-engineering for edge cases
Choosing intelligence type before understanding requirements






